Hash table. Open addressing strategy
Chaining is a good way to resolve collisions, but it has additional memory cost to store the structure of linked-lists. If entries are small (for instance integers) or there are no values at all (set ADT), then memory waste is comparable to the size of data itself. When hash table is based on the open addressing strategy, all key-value pairs are stored in the hash table itself and there is no need for external data structure.
Collision resolution
Let's consider insertion operation. If the slot, key is hashed to, turns out to be busy algorithm starts seeking for a free bucket. It starts with the hashed-to slot and proceeds in a probe sequence, until free bucket is found. There are several well known probe sequences:
- linear probing: distance between probes is constant (i.e. 1, when probe examines consequent slots);
- quadratic probing: distance between probes increases by certain constant at each step (in this case distance to the first slot depends on step number quadratically);
- double hashing: distance between probes is calculated using another hash function.
Open addressing strategy requires, that hash function has additional properties. In addition to performing uniform distribution, it should also avoid clustering of hash values, which are consequent in probe's order.
Linear probing illustration
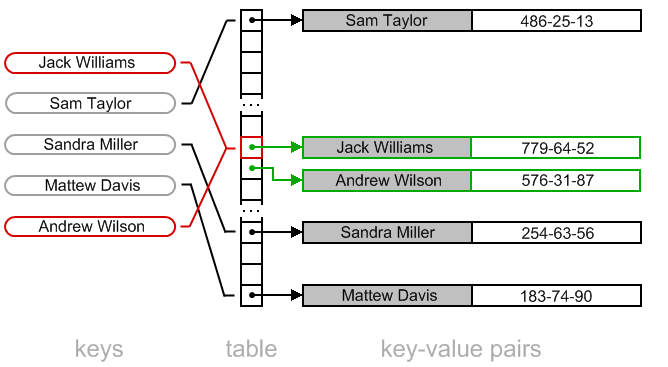
Removal operation
There are several nuances, when removing a key from hash table with open addressing. Consider following situation:
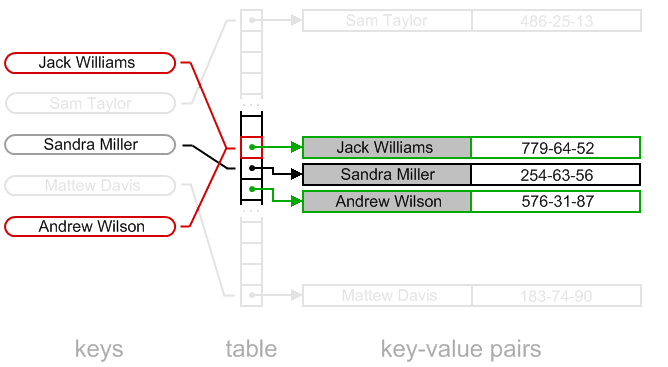
If algorithm simply frees "Sandra Miller" bucket, structure of the table will get broken. Algorithm won't succeed trying to find "Andrew Wilson" key. Indeed, "Andrew Wilson" key is hashed to the "red slot". The slot contains different key and linear probing algorithm will try to find "Andrew Wilson" in the consequent bucket, but it is empty:
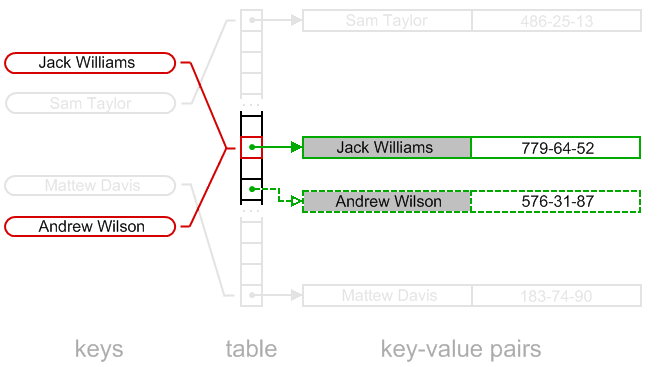
The solution is as following. Instead of just erasing the key, algorithm writes special "DELETED" value to the slot.
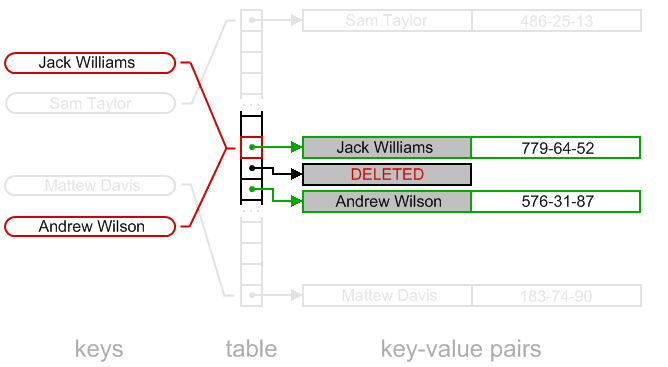
Now lookup algorithm will work properly. Insertion algorithm should reuse deleted slots, when possible.
Note. This algorithm resolves problem, but with time hash table will become clogged with "DELETED" entries, which badly affects performance. If hash table should allow items' removal, then chaining is more preferable way to resolve collisions.
Complexity analysis
Hash tables based on open addressing is much more sensitive to the proper choice of hash function. In assumption, that hash function is good and hash table is well-dimensioned, amortized complexity of insertion, removal and lookup operations is constant.
Performance of the hash tables, based on open addressing scheme is very sensitive to the table's load factor. If load factor exceeds 0.7 threshold, table's speed drastically degrades. Indeed, length of probe sequence is proportional to (loadFactor) / (1 - loadFactor) value. In extreme case, when loadFactor approaches 1, length of the sequence approaches infinity. In practice it means, that there are no more free slots in the table and algorithm will never find place to insert a new element. Hence, this kind of hash tables should support dynamic resizing in order to be efficient.
Open addressing vs. chaining
| Chaining | Open addressing | |
| Collision resolution | Using external data structure | Using hash table itself |
| Memory waste | Pointer size overhead per entry (storing list heads in the table) | No overhead 1 |
| Performance dependence on table's load factor | Directly proportional | Proportional to (loadFactor) / (1 - loadFactor) |
| Allow to store more items, than hash table size | Yes | No. Moreover, it's recommended to keep table's load factor below 0.7 |
| Hash function requirements | Uniform distribution | Uniform distribution, should avoid clustering |
| Handle removals | Removals are ok | Removals clog the hash table with "DELETED" entries |
| Implementation | Simple | Correct implementation of open addressing based hash table is quite tricky |
1 Hash tables with chaining can work efficiently even with load factor more than 1. At the same time, tables based on open addressing scheme require load factor not to exceed 0.7 to be efficient. Hence, 30% of slots remain empty, which leads to obvious memory waste.
Code snippets
Code below implements linear probing. Current implementation is protected against entering infinite loop.
Java implementation
public class HashEntry {
private int key;
private int value;
HashEntry(int key, int value) {
this.key = key;
this.value = value;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
public int getKey() {
return key;
}
}
public class DeletedEntry extends HashEntry {
private static DeletedEntry entry = null;
private DeletedEntry() {
super(-1, -1);
}
public static DeletedEntry getUniqueDeletedEntry() {
if (entry == null)
entry = new DeletedEntry();
return entry;
}
}
public class HashMap {
private final static int TABLE_SIZE = 128;
HashEntry[] table;
HashMap() {
table = new HashEntry[TABLE_SIZE];
for (int i = 0; i < TABLE_SIZE; i++)
table[i] = null;
}
public int get(int key) {
int hash = (key % TABLE_SIZE);
int initialHash = -1;
while (hash != initialHash
&& (table[hash] == DeletedEntry.getUniqueDeletedEntry() || table[hash] != null
&& table[hash].getKey() != key)) {
if (initialHash == -1)
initialHash = hash;
hash = (hash + 1) % TABLE_SIZE;
}
if (table[hash] == null || hash == initialHash)
return -1;
else
return table[hash].getValue();
}
public void put(int key, int value) {
int hash = (key % TABLE_SIZE);
int initialHash = -1;
int indexOfDeletedEntry = -1;
while (hash != initialHash
&& (table[hash] == DeletedEntry.getUniqueDeletedEntry() || table[hash] != null
&& table[hash].getKey() != key)) {
if (initialHash == -1)
initialHash = hash;
if (table[hash] == DeletedEntry.getUniqueDeletedEntry())
indexOfDeletedEntry = hash;
hash = (hash + 1) % TABLE_SIZE;
}
if ((table[hash] == null || hash == initialHash)
&& indexOfDeletedEntry != -1)
table[indexOfDeletedEntry] = new HashEntry(key, value);
else if (initialHash != hash)
if (table[hash] != DeletedEntry.getUniqueDeletedEntry()
&& table[hash] != null && table[hash].getKey() == key)
table[hash].setValue(value);
else
table[hash] = new HashEntry(key, value);
}
public void remove(int key) {
int hash = (key % TABLE_SIZE);
int initialHash = -1;
while (hash != initialHash
&& (table[hash] == DeletedEntry.getUniqueDeletedEntry() || table[hash] != null
&& table[hash].getKey() != key)) {
if (initialHash == -1)
initialHash = hash;
hash = (hash + 1) % TABLE_SIZE;
}
if (hash != initialHash && table[hash] != null)
table[hash] = DeletedEntry.getUniqueDeletedEntry();
}
}
C++ implementation
class HashEntry {
private:
int key;
int value;
public:
HashEntry(int key, int value) {
this->key = key;
this->value = value;
}
int getKey() {
return key;
}
int getValue() {
return value;
}
void setValue(int value) {
this->value = value;
}
};
class DeletedEntry: public HashEntry {
private:
static DeletedEntry *entry;
DeletedEntry() :
HashEntry(-1, -1) {
}
public:
static DeletedEntry *getUniqueDeletedEntry() {
if (entry == NULL)
entry = new DeletedEntry();
return entry;
}
};
DeletedEntry *DeletedEntry::entry = NULL;
const int TABLE_SIZE = 128;
class HashMap {
private:
HashEntry **table;
public:
HashMap() {
table = new HashEntry*[TABLE_SIZE];
for (int i = 0; i < TABLE_SIZE; i++)
table[i] = NULL;
}
int get(int key) {
int hash = (key % TABLE_SIZE);
int initialHash = -1;
while (hash != initialHash && (table[hash]
== DeletedEntry::getUniqueDeletedEntry() || table[hash] != NULL
&& table[hash]->getKey() != key)) {
if (initialHash == -1)
initialHash = hash;
hash = (hash + 1) % TABLE_SIZE;
}
if (table[hash] == NULL || hash == initialHash)
return -1;
else
return table[hash]->getValue();
}
void put(int key, int value) {
int hash = (key % TABLE_SIZE);
int initialHash = -1;
int indexOfDeletedEntry = -1;
while (hash != initialHash && (table[hash]
== DeletedEntry::getUniqueDeletedEntry() || table[hash] != NULL
&& table[hash]->getKey() != key)) {
if (initialHash == -1)
initialHash = hash;
if (table[hash] == DeletedEntry::getUniqueDeletedEntry())
indexOfDeletedEntry = hash;
hash = (hash + 1) % TABLE_SIZE;
}
if ((table[hash] == NULL || hash == initialHash) && indexOfDeletedEntry
!= -1)
table[indexOfDeletedEntry] = new HashEntry(key, value);
else if (initialHash != hash)
if (table[hash] != DeletedEntry::getUniqueDeletedEntry()
&& table[hash] != NULL && table[hash]->getKey() == key)
table[hash]->setValue(value);
else
table[hash] = new HashEntry(key, value);
}
void remove(int key) {
int hash = (key % TABLE_SIZE);
int initialHash = -1;
while (hash != initialHash && (table[hash]
== DeletedEntry::getUniqueDeletedEntry() || table[hash] != NULL
&& table[hash]->getKey() != key)) {
if (initialHash == -1)
initialHash = hash;
hash = (hash + 1) % TABLE_SIZE;
}
if (hash != initialHash && table[hash] != NULL) {
delete table[hash];
table[hash] = DeletedEntry::getUniqueDeletedEntry();
}
}
~HashMap() {
for (int i = 0; i < TABLE_SIZE; i++)
if (table[i] != NULL && table[i]
!= DeletedEntry::getUniqueDeletedEntry())
delete table[i];
delete[] table;
}
};

| Previous: Chaining | Next: Dynamic resizing |
Contribute to AlgoList
Liked this tutorial? Please, consider making a donation. Contribute to help us keep sharing free knowledge and write new tutorials.
Every dollar helps!